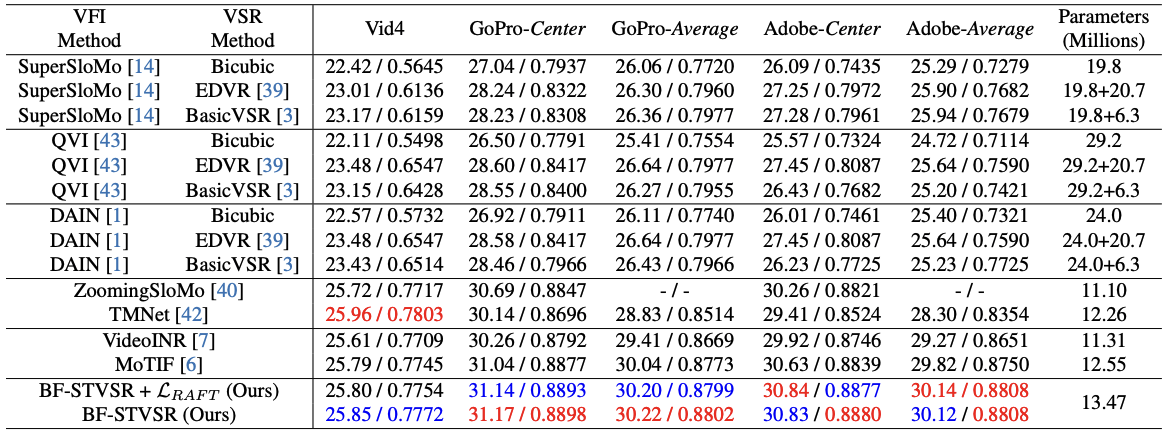
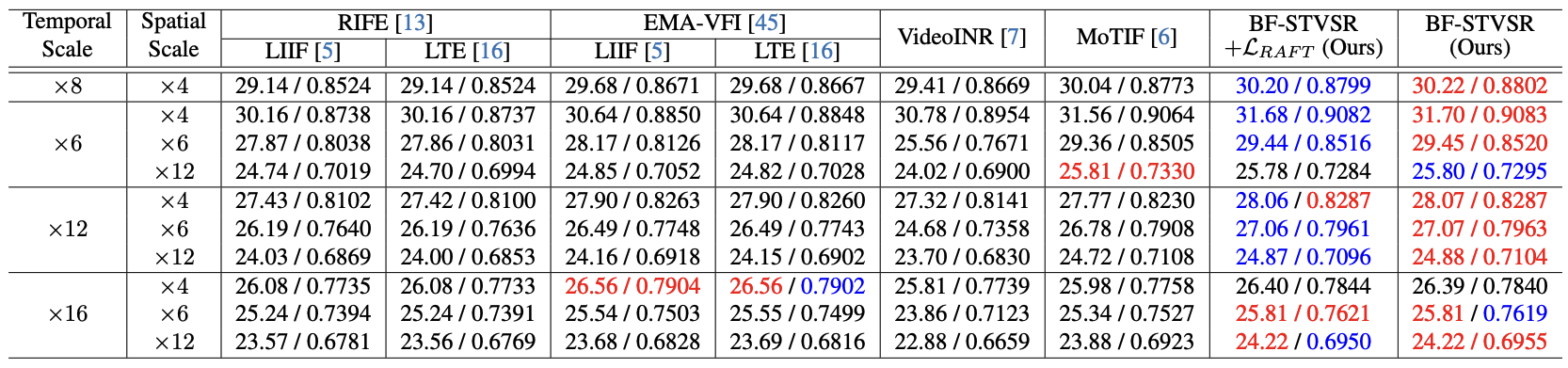
Method
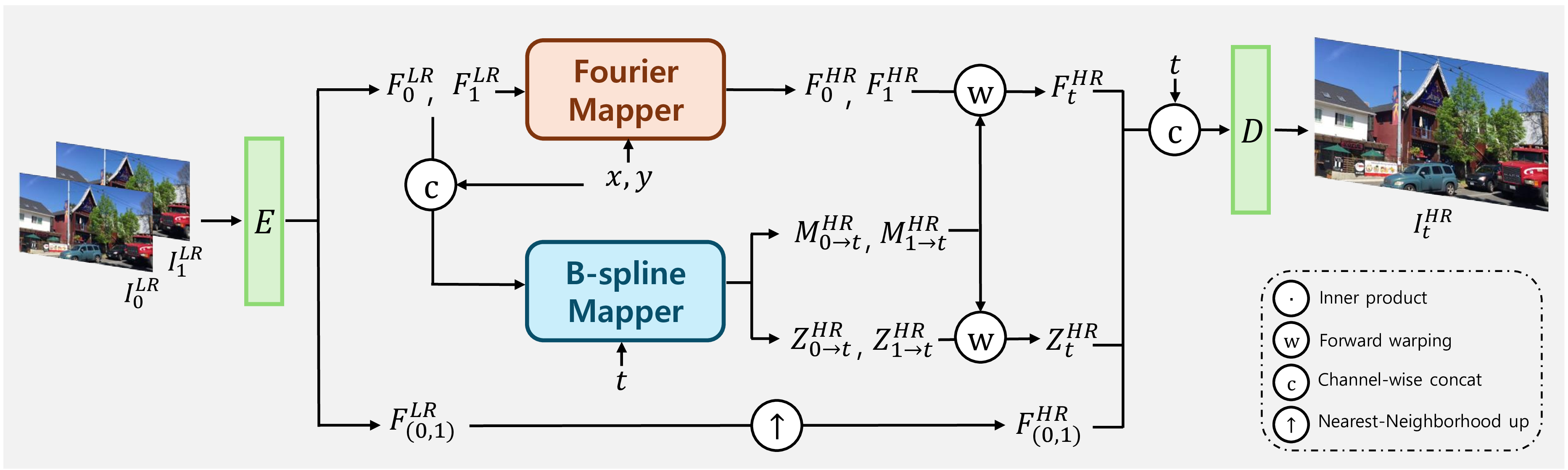
BF-STVSR Overview
First, two input frames are encoded as low-resolution feature maps. Based on these features, Fourier Mapper predicts the dominant frequency information, while B-spline Mapper predicts smoothly interpolated motion, which is then processed into optical flows at an arbitrary time t. The frequency information is temporally propagated by being warped with the optical flows. Finally, the warped frequency information is decoded to generate high-resolution interpolated RGB frame.
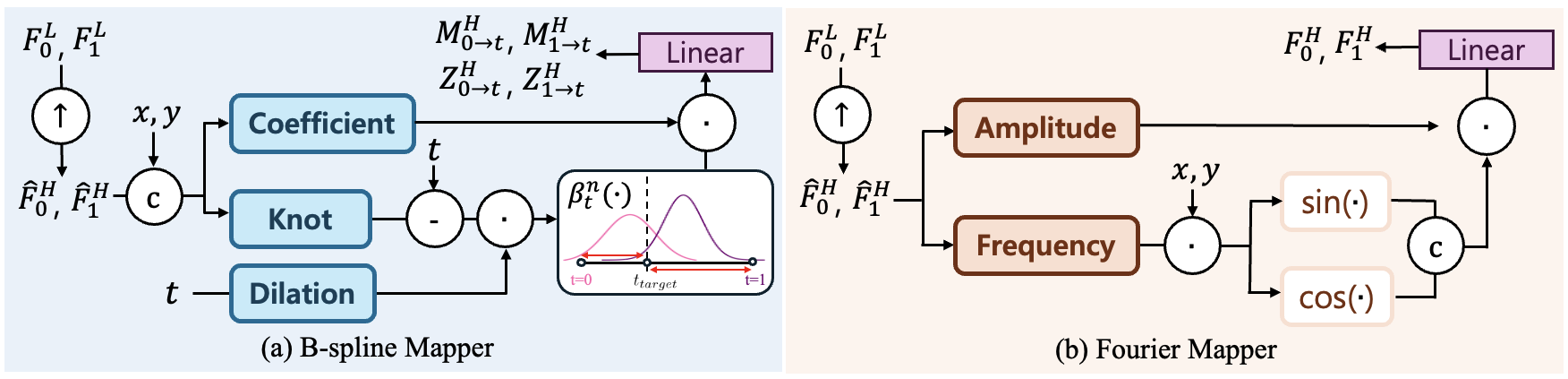
B-spline Mapper and Fourier Mapper
(a) B-spline Mapper estimates B-spline coefficients to model inherent motion, which smoothly interpolates motion features temporally. (b) Fourier Mapper estimates the dominant frequency and its amplitude to capture fine-detail information from the given frames.